With seemingly exponential acceleration of foundation model capabilities, it is becoming easier for AI product teams to build performant agents. These teams are now being tasked with managing these agents at a greater scale and a wider variety of use cases than previously contemplated. To do this well, they need to implement an AI data flywheel powered by a modern, agent-first approach to observability.
This post was heavily inspired by a conversation between Scott Clark, Distributional co-founder and CEO, and Jason Liu of the Developer Experience team at OpenAI. You can watch this here (especially minutes 1 - 15):
Agent observability hierarchy
Scale alone breaks the former paradigm of “I can look at most of my traces to understand how my agent is behaving” that used to be the gold standard of online agent observability. But to complicate things further, to leverage these enhanced capabilities of the foundation models it makes sense to let them make many more decisions about the workflow to get to an answer—which creates a mess of tool calls, context retrieval, multi-prompt chains, and multiple LLM calls with no human in the loop. Add agent complexity with this scale, and agent observability is fully broken.
These AI product teams need a modern agent observability stack of capabilities. At Distributional, we think of this as a three-component hierarchy of agent observability: Logging, Monitoring, and Analytics.
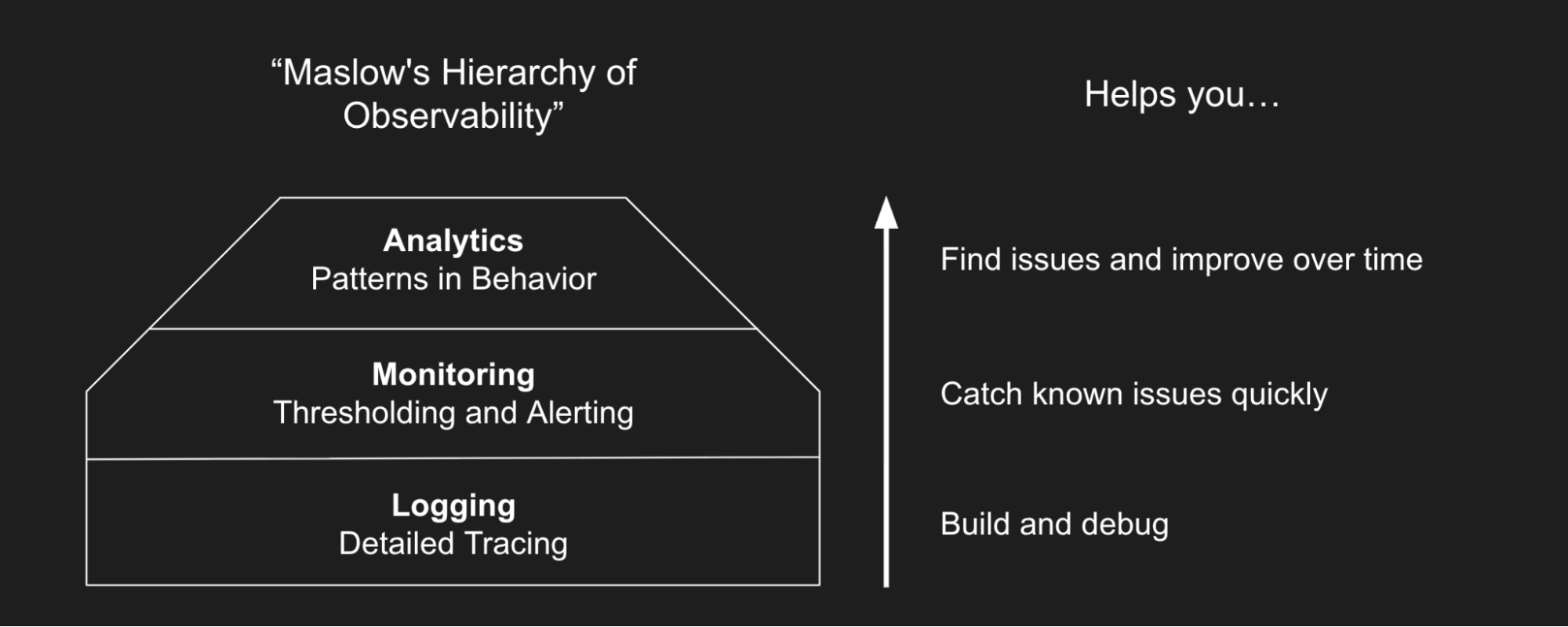
How analytics fits with logging and monitoring
Most teams have already started to repair their agent observability stack. Richer agent logging that includes sessions, traces, and spans is widely available through OpenTelemetry and plenty of open source products that support it. Teams often start logging to build and debug their agents. These logs are fed into an eval tool that makes it easy to iterate on prompts or design custom functions to score or classify outputs. Logging what has happened is the first step of any observability stack, and for agents it is critical to have multiple levels reported (session, trace, and span).
Similarly, AI product teams have invested in agent-specific monitoring that tracks, thresholds, and gives fast response alerts on deviations from thresholds on known cost, speed, and quality metrics. These monitoring solutions are designed to trade off richness of analysis for timeliness—you need to know when cost has spiked or your agent is down. These have been redesigned to account for LLM-as-judge metrics and agent specific evals, as well as tokens, feedback, and other standard speed, cost, and quality metrics for agents.
But there is a third component that every team needs to implement to complete the AI feedback lifecycle: Analytics. Think of analytics as similar to product analytics for a traditional software product, but instead of treating the user as the atomic unit you treat the agent as such. Whereas monitoring trades off richness for timeliness, analytics trades off timeliness for richness.
Analytics are particularly important for agents due to their complexity. Logging and monitoring is sufficient if you know everything you need to track for a relatively straightforward software product. But when you are deferring cognitive tasks to the agent and the agent is deciding which tools, context, models, or steps to take, it is impossible to know all the issues that could arise. Similarly, most agents are flexible enough that users could make a wide variety of diverse requests. Without knowing in advance how users are going to use the agent or how the agent will behave when they do, there are plenty of unknown unknowns that could have a significant impact on agent performance.
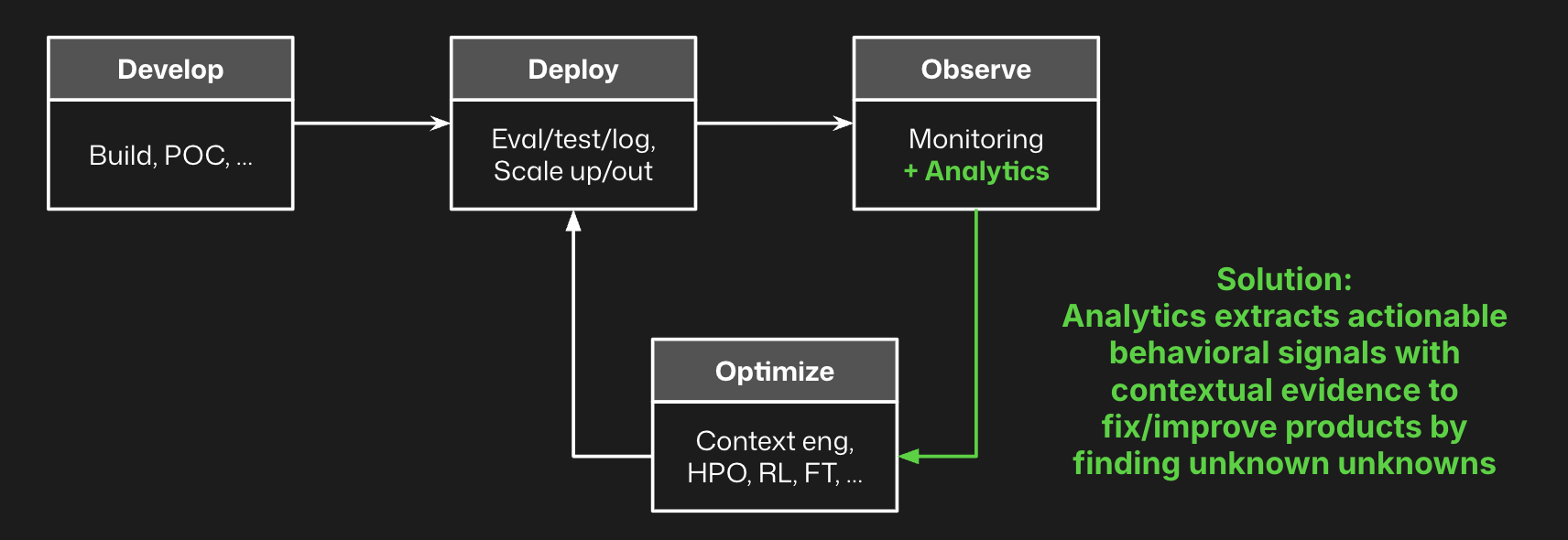
If you pair logging and monitoring with analytics, you can complete this feedback loop. You log traces to provide information on agent behavior, monitoring to threshold known issues, and analytics to discover new issues to be fixed and monitored.
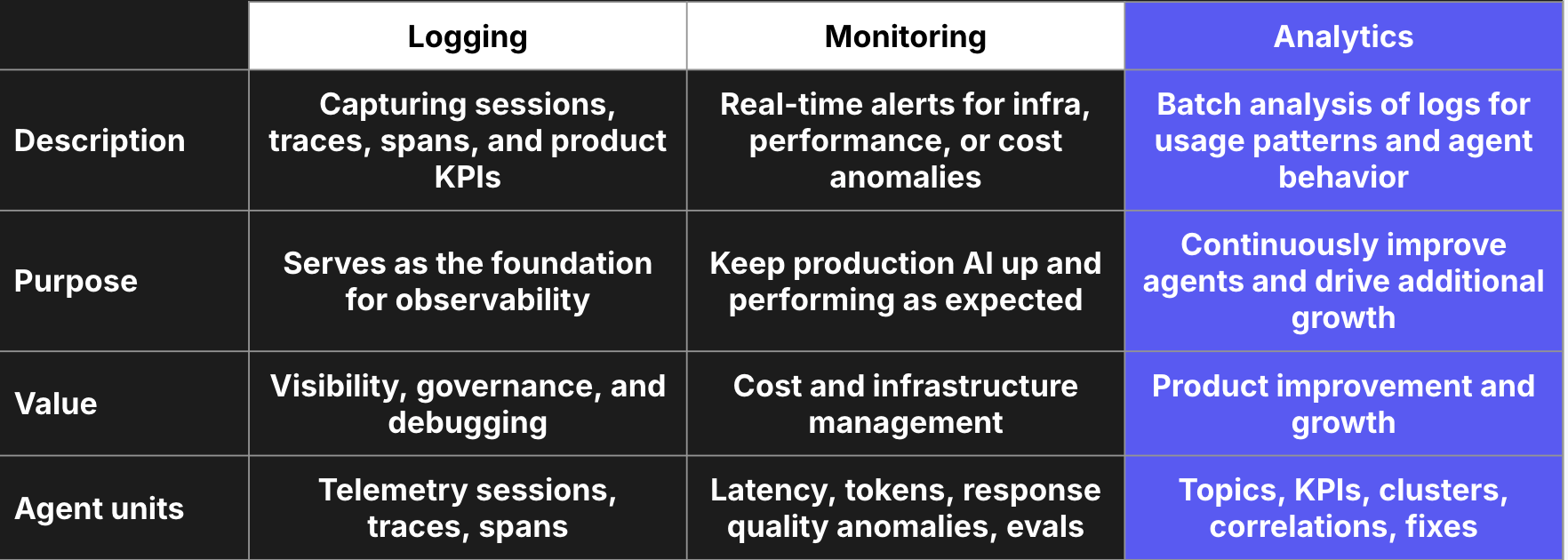
Benefits of this approach to agent observability
Agent-specific logging and monitoring are a good start, and can begin to give you visibility into whether things are working. By adding analytics to the agent observability stack, however, you enable continuous improvement of the agent. Analytics surfaces signals that are otherwise unknown, and supports these signals with contextual evidence—specific logs that represent the issue or opportunity to improve.
Armed with this evidence, AI product teams can add these specific logs to their offline evals, reward functions for reinforcement learning pipelines, or datasets for fine-tuning processes to optimize agent performance. These analytics can also guide simpler fixes, such as prompt improvements, context refinement, or tool adjustments that can boost performance.
Next
Distributional is a free, open, and installable platform for agent analytics. Try it today and quickly learn how it complements your existing agent observability stack. We are also always happy to learn more about your use case and enterprise needs, so reach out to contact@distributional.com with any questions.
Subscribe to DBNL
Thank you for your submission!
Oops! Something went wrong while submitting the form.

